This document provides a step-by-step guide to build a Data Fusion data pipeline that reads data from an IBM DB2 database and writes to GCP, specifically BigQuery.
Prerequisite
Before starting to build a Cloud Data Fusion pipeline that reads data from an IBM DB2 database and writes to BigQuery, make sure DB2 is set up and accessible from a Cloud Data Fusion instance.
Instructions
Upload the DB2 database driver to Cloud Data Fusion.
Go to Hub.
Click on Drivers and select the IBM DB2 driver from the list.
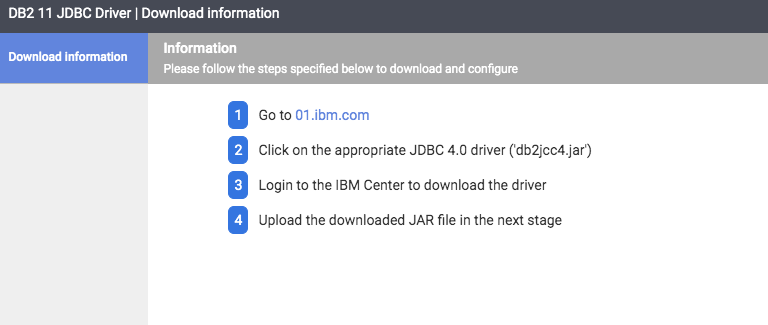
Clicking on the IBM DB2 icon asks you to follow 2 a two-step process.
Download the IBM DB2 driver based on the instructions provided.
Find the db2jcc4.jar in the downloaded zip file and upload it to Cloud Data Fusion by clicking on the Deploy.
Provide the configurations by clicking on the Driver configuration.
Note the name of the driver specified (db211 in this case) which will be used while configuring the plugins. Click Finish to complete the driver uploading process.





| Warning |
|---|
If you get ClassNotFoundExceptionthe error ‘get ClassNotFoundException’, it is likely that the fully qualified name of the DB2Driver class is different than from “com.ibm.db2.jcc.DB2Driver”. Open the jar in the editor and locate the DB2Driver class (for example com/ibm/db2/jcc/DB2Driver.class in this case). Specify the appropriate fully qualified class name for the DB2Driver. |
Deploy IBM DB2 plugins from Hub.
Go back to Hub again and find the DB2 plugins under plugins section.
Click on the DB2 plugins and then Deploy them on the Cloud Data Fusion instance.
Once plugins are deployed, click on Create Pipeline to go to Data pipeline studioPipeline Studio.
Create data pipeline.
Select the IBM DB2 source from the list of sources.
Configure the DB2 plugin by clicking on the properties. Provide the basic configurations as follows:


where,
Driver name: Name of the driver provided while uploading the DB2 driver.
Host: Host where the DB2 server is running.
Port: Port of DB2 server.
Database: Name of the DB2 database.
Import Query: Select query to import data from the DB2 table.
Also provide credentials required to connect to the DB2 server.
Once the details are filled in, click on the GetSchema button followed by Execute to import schema from the source table as:
Click Apply to use this schema as an output schema for the plugin.
Click on the sink and choose BigQuery sink.

Configure BigQuery sink as below specifically by providing the Dataset and Table name as:

Click on Deploy once the pipeline is built.


Run the data pipeline.
Click on Run to run the pipeline.









| Tip |
|---|
Once the above pipeline succeeds, Preview the written data in BigQuery. |
Related articles
| Filter by label (Content by label) | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
...