This document shows you how to configure CloudSQL for MySQL with Cloud Data Fusion (CDF).
Before you begin
Make sure these prerequisites are in place before you follow the steps in this guide.
Ensure that you have the following roles in IAM for the service account,
service-<project-number>@gcp-sa-datafusion.iam.gserviceaccount.com:Cloud SQL Admin
Cloud Data Fusion Admin
Cloud Data Fusion API Service Agent
Create a CloudSQL (MySQL) instance, test database, and user.
In the Google Cloud Console, navigate to APIs and Services.
Click Enable APIS and Services.

Search for Cloud SQL Admin API.

Choose the Cloud SQL Admin API. Click Enable.

Instructions
Obtain the JDBC Driver JAR file by building it using the instructions at https://github.com/GoogleCloudPlatform/cloud-sql-jdbc-socket-factory
You would have to use
mvn -P jar-with-driver-and-dependencies clean package -DskipTests
to build the JAR instead of the command in README from the above git repo.
Go to Cloud Data Fusion Wrangler.

3. If this is the first time you are configuring CloudSQL for MySQL, click on the Add Connection button from the Wrangler screen and choose Database.

4. Click “Google Cloud SQL for MySQL.”

5. Upload the previously built JAR as illustrated, and click Next.


6. Click Finish to complete the upload.

7. Once the driver has been uploaded you will see a green check mark indicating that your driver has been installed.

Cloud SQL instances with Private IP cannot currently be accessed using Wrangler. So the following instructions will not work for Private IP instances. However, Private IP Cloud SQL instances can still be accessed by creating a pipeline, which will run using Cloud Dataproc. See Accessing Cloud SQL in pipelines for instructions.
8. Click the Google Cloud SQL for MySQL to create a new connection. Once the connection modal opens click on the Advanced link if present.
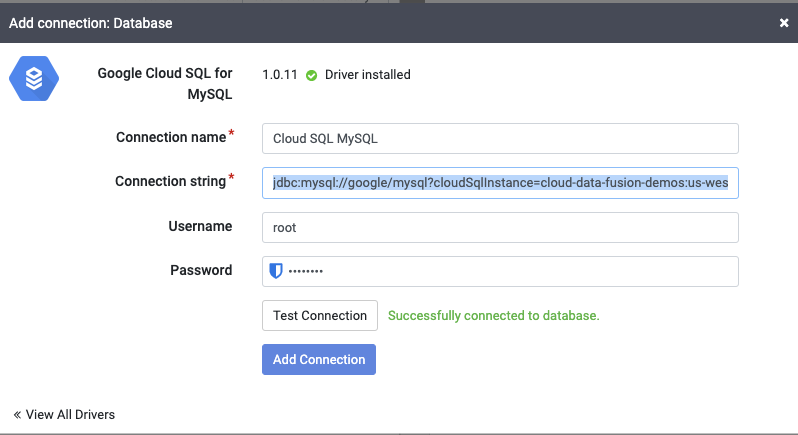
9. Enter your connection string as:
jdbc:mysql://google/<database>?cloudSqlInstance=<instance-connection-name>&socketFactory=com.google.cloud.sql.mysql.SocketFactory&useSSL=false
For example:
jdbc:mysql://google/mysql?cloudSqlInstance=cloud-data-fusion-demos:us-west1:mysql&socketFactory=com.google.cloud.sql.mysql.SocketFactory&useSSL=false
where <database> represents the database you created in the prerequisites section, and <instance-connection-name> refers to your instance connection name as displayed in the overview tab of of the instance details page.
10. Enter the username and the password you configured for this CloudSQL instance.
11. Click Test Connection to verify that the connection can successfully be established with the database.
12. Click Add Connection to complete the task.
Once you’ve completed all the steps you will be able to click on the newly defined database connection and see the list of tables for that database.
Building the MySQL Socket Factory Driver
The driver that is used for CloudSQL with MySQL can be built from https://github.com/GoogleCloudPlatform/cloud-sql-jdbc-socket-factory/blob/master/connector-j-8/pom.xml.
Accessing CloudSQL in pipelines
Perform steps 1-6 in the Wrangler section above.
Open Pipeline Studio.
From the plugin palette on the left, drop the Cloud SQL source plugin to the canvas and click Properties.
Specify the plugin name as cloudsql-mysql.
Specify the connection string as below:
jdbc:mysql://google/<database>?cloudSqlInstance=<instance-name>&socketFactory=com.google.cloud.sql.mysql.SocketFactory&useSSL=false
For example:
jdbc:mysql://google/mysql?cloudSqlInstance=cloud-data-fusion-demos:us-west1:mysql&socketFactory=com.google.cloud.sql.mysql.SocketFactory&useSSL=false
where <database> represents the database you created in the prerequisites section, and <instance-name> refers to you instance connection name as displayed in the overview tab of of the instance details page, e.g:

6. Enter the query that you would like to import data from as the Import Query.

7. Enter the username and password to use for the database. You can also use a secure macro for the password.

8. Click Get Schema to populate the schema of the plugin.
9. Configure the rest of the pipeline and deploy the pipeline.
Note: Pipeline preview will not currently work with CloudSQL MySQL Private IP instances. However, deploying the pipeline and executing using Cloud Dataproc should still work.